
Translational Psychiatry:利用美国和澳大利亚队列中的临床变量开发多因素痴呆预测模型
2025-01-26 xiongjy MedSci原创 发表于陕西省

多因素痴呆预测模型中APOE基因型是最重要的预测因子,神经网络模型表现最佳。ADNI和AIBL数据集之间的APOE基因型分布差异导致模型性能差异,建议未来研究进一步整合不同队列数据以提高模型的泛化能力
全球有超过 5500 万人患有痴呆,这一数字每年迅速增加 1000 万例,提高痴呆诊断能力和诊断率是当务之急。现有的使用非神经影像学临床测量的痴呆预测模型在识别疾病的能力方面受到限制,因此基于诊断成像的机器学习模型在实际临床应用中的效用有限。
本研究旨在开发一个基于临床变量的多因素痴呆预测模型,利用来自美国阿尔茨海默病神经影像学计划(ADNI)和澳大利亚老年学成像、生物标志物与生活方式研究(AIBL)数据库的数据,采用机器学习算法重新评估临床变量在痴呆诊断中的潜力。研究使用了21种临床变量,包括医学历史、血液学和其他血液检测结果,以及APOE基因型。树基机器学习算法和人工神经网络被应用于数据分析。

研究结果表明,APOE基因型是区分痴呆患者和健康对照的最佳预测因子。结合ADNI和AIBL数据集后,使用神经网络模型的敏感性为0.83,阳性预测值(PPV)为0.73,表明该模型在诊断痴呆时表现较好。然而,在将ADNI和AIBL队列分开进行单独训练和测试时,模型的预测能力显著降低。训练在ADNI数据集上的模型,测试时在AIBL数据集上,敏感性显著下降,而训练在AIBL数据集上的模型测试时在ADNI数据集上,则表现为较高的假阳性率。研究还发现,这种性能差异与APOE基因型在两组中的分布差异有关,ADNI组中的痴呆患者较多,而AIBL组的健康对照中存在较多的APOE4携带者。
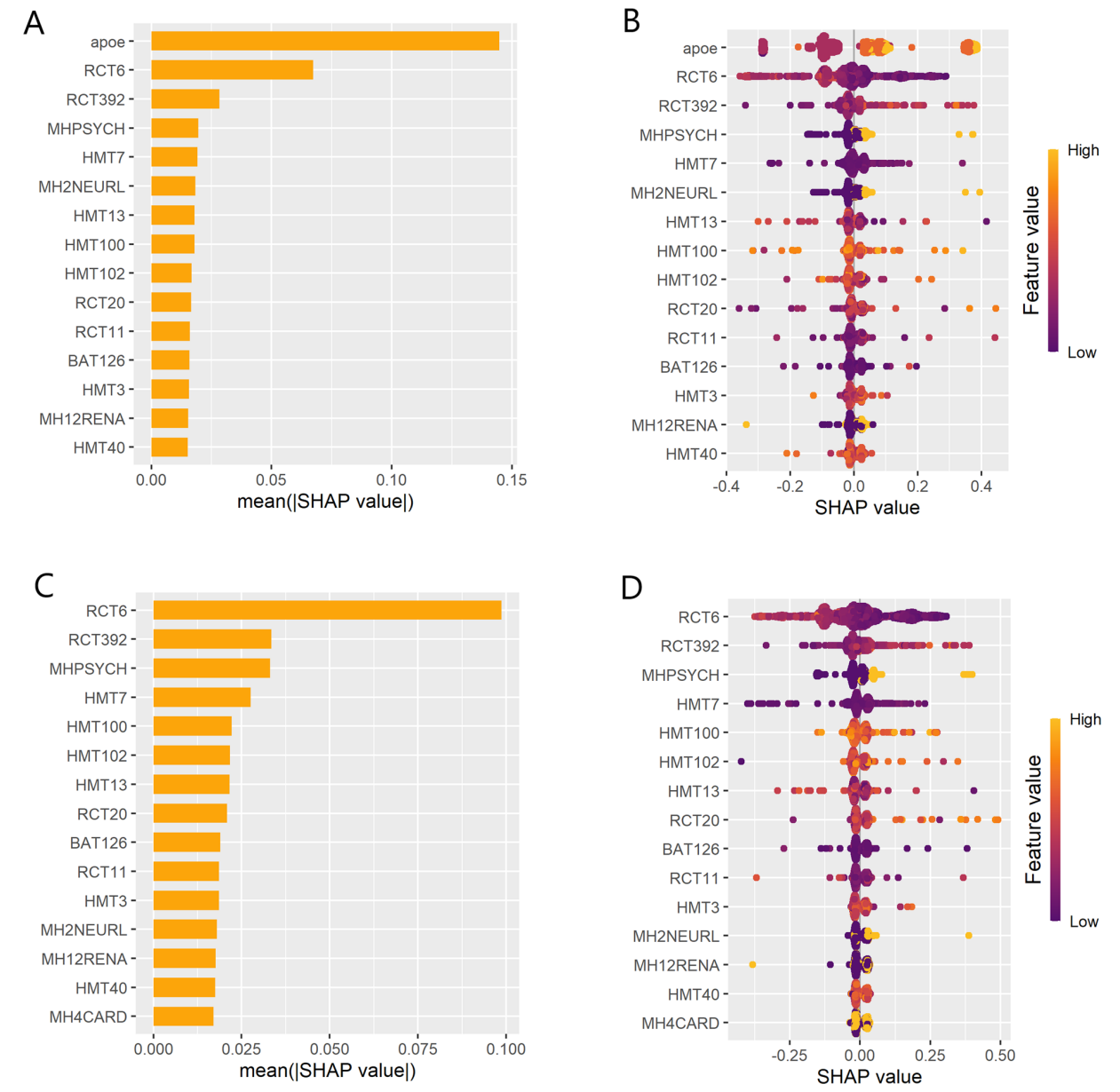
图1:使用SHAP分析模型的特征重要性
在统计分析中,研究者首先确保了ADNI和AIBL队列中的特征变量的一致性,接着利用多种机器学习算法,包括分类回归树(CART)、随机森林、梯度提升机(GBM)和人工神经网络,对数据进行了训练和验证。通过交叉验证,模型表现的主要性能指标包括敏感性、阳性预测值、特异性、阴性预测值以及AUC(曲线下面积)。特别是,研究强调了APOE基因型对模型的贡献,通过SHAP分析确认,APOE基因型对痴呆诊断的贡献最大。
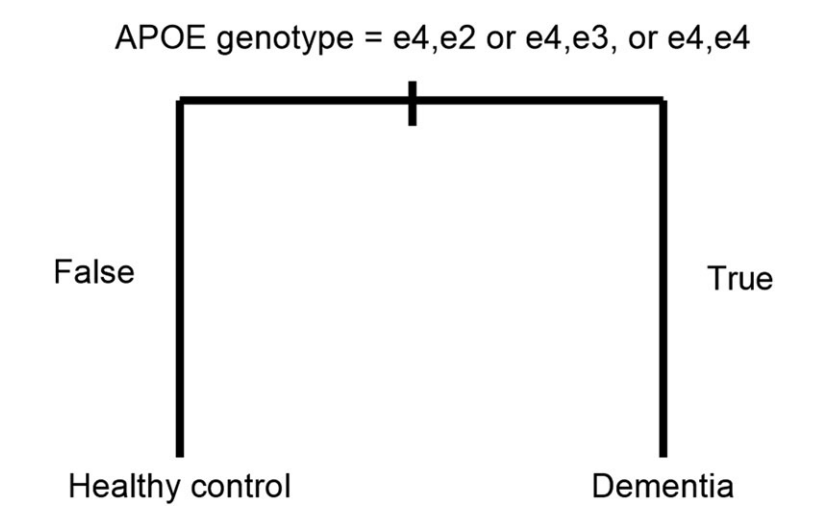
图2:分类回归树(CART)模型决策树,训练数据集为ADNI,测试数据集为AIBL,或训练数据集为AIBL,测试数据集为ADNI
研究结果还揭示了现有痴呆预测模型的局限性,尤其是在数据集不一致的情况下,模型的泛化能力和解释性受到限制。因此,未来的研究应当集中于整合不同临床队列数据,以提高模型的准确性和普适性,并探讨常规APOE基因检测在痴呆诊断中的应用。
原始出处:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言














#痴呆# #预测模型# #机器学习# #APOE基因型#
0