
JCO社论:组织病理学深度学习AI是精准肿瘤学的未来吗?
2024-09-26 测序中国 测序中国 发表于上海

文章分享了AI和DL在精准肿瘤学的应用进展,并探讨了相关挑战。
自21世纪初伊马替尼用于治疗慢性粒细胞白血病以来,精准肿瘤学一直是癌症研究的焦点。从那时起,癌症研究主要集中于发现肿瘤中的分子靶点,这些分子靶点可以通过生物标志物来识别,并通过特定的治疗干预来靶向。人工智能(AI)具有引领下一次精准肿瘤学变革的潜力,其标志是基于AI的肿瘤学研究和开发的指数增长。
近日,Journal of Clinical Oncology发表社论文章“Is Histopathology Deep Learning Artificial Intelligence the Future of Precision Oncology?”,分享了AI和DL在精准肿瘤学的应用进展,并探讨了相关挑战。

深度学习(DL)是AI的一个子集,可以利用癌症行为、基因组学和组织病理学之间的关系。DL使用嵌入人工神经网络中的数学方程,从数据(如数字组织病理学切片)中提取抽象和复杂的特征和模式。深度是指这些神经网络中的多个层,使算法能够从相对简单的输入中开发复杂的数据表示。这种深度,加上大型数据集和强大的计算能力,赋予了DL强大的功能。在特定癌症类型和泛癌研究中,DL算法已经被越来越多地用于研究新的预测和预后生物标志物。
乳腺癌是第一个利用DL进行组织病理学评估的癌症类型之一,因为它建立了生物标志物驱动的治疗。同源重组修复缺陷(HRD)是乳腺癌和卵巢癌最重要的预测生物标志物之一。HRD对多聚(ADP-核糖)聚合酶抑制剂和铂类化疗敏感。HRD被归因于同源重组途径中的异常,最显著的是由于BRCA1和BRCA2突变。目前,HRD常通过依赖于复杂分子检测的专有伴随诊断分析来确定。
DeepHRD是一种Bergstrom团队新开发的DL算法,代表了一种创新的HRD检测方法。(点击查看相关报道)DeepHRD通过使用AI直接从数字组织病理学切片中检测HRD,绕过了大量和昂贵的分子检测。使用弱监督卷积神经网络(CNN)和多示例学习(MIL),该研究团队使用苏木精和曙红染色的完整切片图像(WSIs)建立了一个预测HRD和预后的模型。CNN通过检测空间特征和模式而被设计用于视觉/图像应用。该模型将WSIs镶嵌成更小的tiles以供处理。MIL是一种弱监督的DL方法,其中图块标签是基于WSI标签假设的,而不需要在图块级别进行更精确的注释。研究团队设计了一个多分辨率工作流程,首先以低(5×)放大率下评估WSI,然后自动选择一个目标区域以更高(20×)放大率进行评估;这模拟了由训练有素的病理学家对组织切片的评估。该模型是使用快速冷冻(FF)样本和福尔马林固定的石蜡包埋(FFPE)载玻片来进行训练。
该研究并不是第一个使用DL来检测HRD的研究,其区别在于建立了一个在多个独立队列中验证的更通用的模型,并通过评估临床结果进一步证明了DeepHRD的临床应用价值。研究团队使用了一些技术来最小化过拟合,包括独立的测试组(验证队列中没有患者被用于训练队列)、平衡训练数据、以及神经网络中节点的随机退出。通过比较受试者工作特征(ROC)曲线下面积(AUC),可以适当地评价模型的性能。在FF和FFPE独立队列中,DeepHRD能够实现中度准确的HRD预测(AUC为0.76-0.81)。研究进一步分析了该模型预测预后的能力,发现与传统的分子检测相比,DeepHRD能够更准确地预测无进展生存期和治疗反应。重要的是,DeepHRD能够识别出一小部分表现出HRD表型但传统分子检测无法识别的患者。为了解释DeepHRD算法的黑盒子内部发生了什么,研究团队对HRD预测的WSI的空间区域进行了识别和注释,发现它们在坏死、巨噬细胞密集和高度密集的炎症组织中富集。
Bergstrom团队克服了在不太常见的癌症类型(如卵巢癌)中应用DL的一些固有挑战,在这些癌症类型中,使用迁移学习不容易获得用于模型训练的大型数据集。迁移学习是一种DL技术,其中算法在一个任务上进行训练(即训练以预测乳腺癌WSI的HRD),并将其重新用作另一个模型的起点(预测卵巢癌WSI的HRD)。与传统的分子检测相比,DeepHRD能够通过总体生存期准确预测卵巢癌预后,并再次识别出更多HRD表型的患者。
该研究为越来越多的肿瘤学中DL应用提供了补充。但这些DL技术很少进入临床实践。要成功地将AI应用于临床肿瘤学,必须解决和克服许多挑战。为了确保DL模型的泛化性和再现性,初始训练需要足够数量的高质量、平衡的数据。韩国近期发表的一项研究使用了与Bergstrom等人类似的技术,使用基于MIL的DL算法对来自癌症基因组图谱(TCGA)的卵巢癌队列进行分析。研究人员能够训练并验证一个预测卵巢癌进展的模型,但与DeepHRD不同的是,该模型与BRCA突变或HRD状态无关。为了开发准确且广泛推广和可重复的模型,研究人员需要超越单一机构的数据和已被广泛用于模型训练的TCGA。
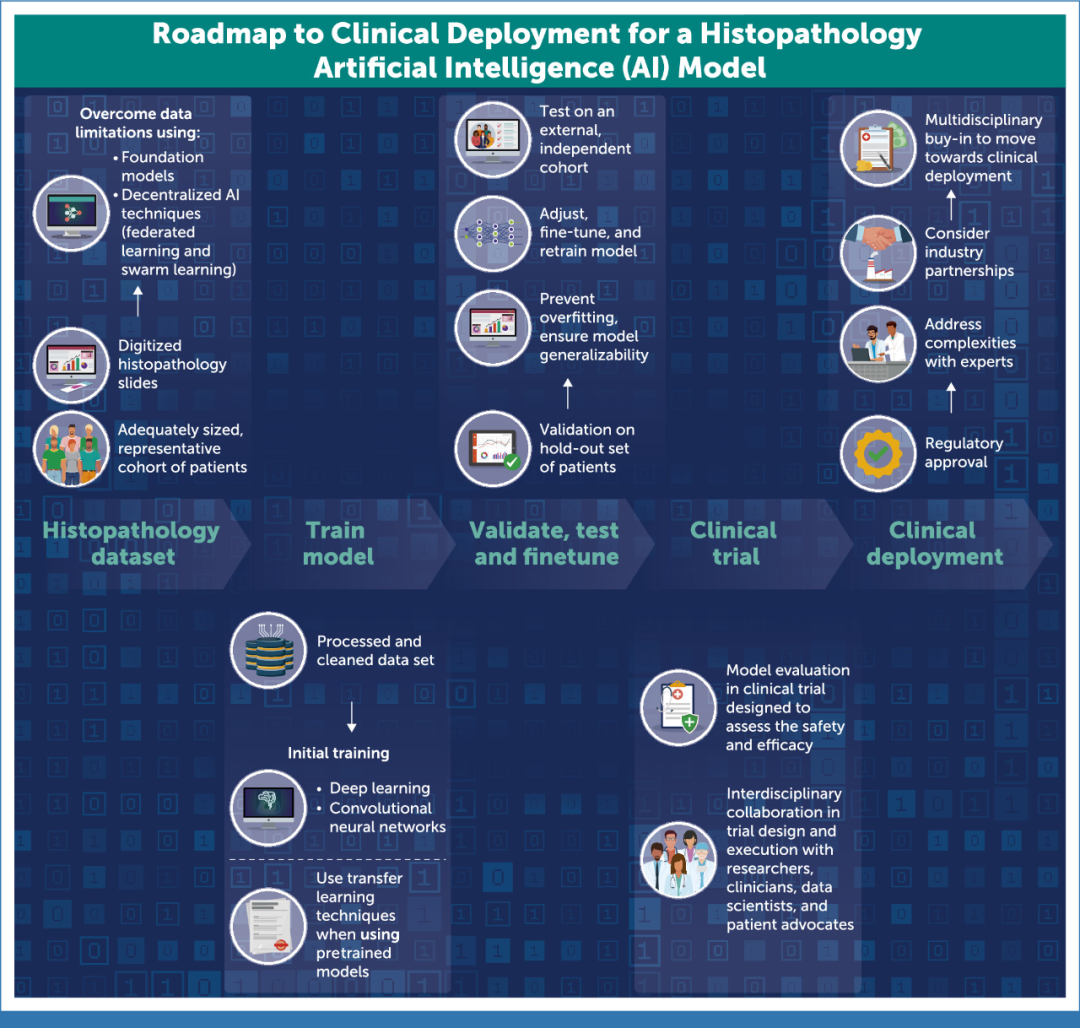
图:在临床肿瘤学中开发和部署基于组织病理学的AI模型所需的基本步骤。它强调了从数据集准备到临床部署的过程,强调了跨学科合作、可靠验证和监管批准的必要性。每一步都是为了确保模型的安全性、有效性和通用性,最终目标是将AI整合到常规癌症治疗中,以改善患者的治疗效果。
大多数已发表的DL研究或者从零开始开发模型,或者从非医学图像(如RESNET)上预先训练的模型开始,然后在数百或数千名患者的队列中进行微调。相比之下,最先进的DL模型通常使用数百万张图像进行训练。由于对患者隐私和数据共享的担忧,获取大量高质量医疗数据可能很困难。新的去中心化AI训练技术,如联邦学习(federated learning)或群体学习(swarm learning),可以帮助克服这些挑战。近期开发的组织病理学基础模型,对数十万个带注释的高质量WSI进行了预训练,也可以解决这些问题。利用基础模型可以使用更少的数据和更少的计算资源,来更快地开发准确的癌症或特定任务模型。
在训练新模型之后,需要在训练过程中没有使用的独立数据上进行验证。这种验证最好包括跨越真实世界变化的多个大型队列。Bergstrom团队指出,其DeepHRD研究的一个优势是纳入了多个独立队列进行验证。然而,每个队列都是对相对较少的患者进行回顾性评估。同样,获得足够大且多样化的验证队列是具有挑战性的。国内和国际合作的临床试验数据可以为验证队列提供丰富的来源,并已成功地在前列腺癌中实施。AI算法验证的最后一步是为评估模型的准确性和实用性而专门设计的临床试验。与传统的基于分子的生物标志物类似,这是临床应用前的关键一步。
监管机构对新型AI算法的批准可能是复杂且具有挑战性的。这个过程通常需要行业合作伙伴或私营公司的发展才能成功实施,并且需要得到临床医生和从业人员的接受和采用。虽然AI为癌症治疗提供了一种范式转变的方法,但将这些模型纳入日常使用还需要时间。此外,将AI成功整合到临床实践中,需要研究人员、临床医生、数据科学家和监管机构之间的通力合作。总之,AI和DL具有革新肿瘤学研究和实践的巨大前景,将促进精准肿瘤学的下一次发展。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言










#深度学习# #精准肿瘤学#
102