
Radiology:简化影像学报告印象的大型语言模型定量评估
2024-09-04 shaosai MedSci原创 发表于上海

数字健康素养定义为患者能够获取、处理和理解电子信息的程度,对于患者至关重要。然而,影像学报告印象充满了技术术语,使得它们对于没有临床背景的个人来说相对难以解释。
众所周知,影像报告是医疗决策的基石,为诊断和治疗计划以及监测疾病进展提供信息。在从前,只有放射科医生和转诊提供者才能访问这些报告,但随着远程医疗和患者门户网站的兴起,以及监管变化增加了对电子健康记录的访问,并改变了患者与其医疗信息的关系。
数字健康素养定义为患者能够获取、处理和理解电子信息的程度,对于患者至关重要。然而,影像学报告印象充满了技术术语,使得它们对于没有临床背景的个人来说相对难以解释。因此,扩大对这些报告的访问可能会加剧患者的焦虑、误解和情绪困扰,特别是在发现异常的情况下。然而,提高放射学知识水平有助于解决这一问题。

近日,发表在Radiology杂志上的一篇研究比较四个公开可用的系统(ChatGPT-3.5和ChatGPT-4, Bard和Bing)在使用不同提示和不同模式生成简化影像学报告印象方面的表现,为临床上对影像报告的进一步管理提供了参考依据。
本项研究在对四个LLM(于2023年7月23日至7月26日访问)的回顾性比较分析中,使用重症医学信息市场(MIMIC)-IV数据库收集750个匿名放射学报告印象,涵盖了一系列成像模式(MRI, CT, US, x线摄影,钼靶)和解剖区域。采用三个不同的提示来评估法学硕士简化报告印象的能力。第一个提示(提示1)是“简化这份放射报告”。第二个提示(提示2)是“我是患者,简化这份放射报告”。最后一个提示(提示3)是“将这份放射学报告简化到7年级水平”。每个提示之后是影像学报告印象,并查询一次。主要结果是通过可读性评分来评估简化。使用四项已建立的可读性指标的平均值来评估可读性。采用非参数Wilcoxon符号秩检验来比较LLM输出的阅读年级水平。
所有四个LLMs都简化了所有提示的影像学报告印象(P < 0.001)。在提示中,LLM之间存在差异。提供患者情境或要求简化为七年级水平降低了所有模型和提示(ChatGPT-4的提示1至提示2除外)输出的阅读等级水平(P < 0.001)。
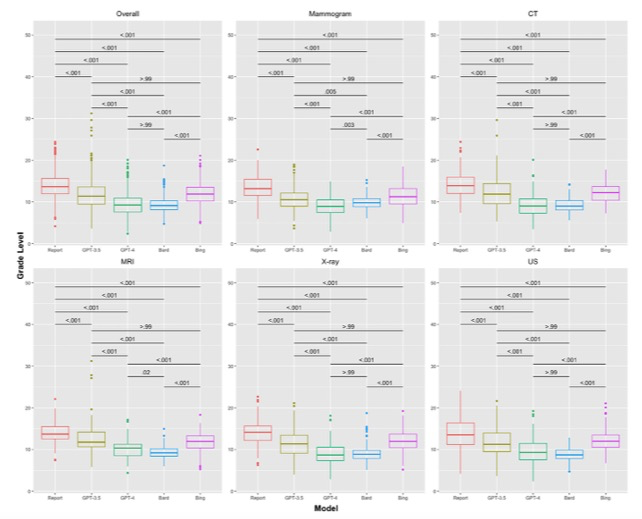
图 箱形图比较了提示1“简化此放射学报告”的大型语言模型(LLM)之间的平均阅读等级水平。对于所有750份报告(总体),并基于成像方式,将LLM输出的阅读等级水平相互比较,并与初始放射科医生指示的报告进行比较
本项研究表明,尽管每个LLM的成功取决于具体的提示措辞,但所有四种模型都简化了所有模式和提示测试的影像学报告印象。
原文出处:
Rushabh Doshi,Kanhai S Amin,Pavan Khosla,et al.Quantitative Evaluation of Large Language Models to Streamline Radiology Report Impressions: A Multimodal Retrospective Analysis.DOI:10.1148/radiol.231593
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言













#chatGPT# #影像学报告#
80