
Nat Mach Intell:哈佛医学院团队开发癌症影像生物标志物的基础模型
2024-06-17 测序中国 测序中国 发表于上海

该基础模型有助于更好、更高效地学习影像生物标志物,并产生了特定任务的模型,在下游任务上显著优于传统的监督和其他预训练模型,尤其是在训练数据集规模非常有限的情况下。
基础模型(Foundation Model)是基于海量数据集训练的大型深度学习神经网络,可以作为各种下游任务的基础,帮数据科学家省去从头开始人工智能(AI)开发的时间,从而更快速、更经济高效地为新应用程序提供支持。例如,基础模型推动了ChatGPT、BERT和CLIP等的成功。
基础模型在医学领域有着巨大的潜力。经过自监督学习预训练(如图像重建)后,基础模型可以应用于特定任务,提高泛化能力,尤其是在数据集较小的情况下。自监督学习在医学影像中的应用主要集中在二维(2D)图像(X射线、全切片图像、皮肤病学图像、眼底图像等)的诊断方面。在预后方面,自监督学习是否有助于训练基础模型用于生物标志物发现呢?
哈佛医学院的研究团队及合作者在Nature Machine Intelligence发表了题为“Foundation model for cancer imaging biomarkers”的文章,研究了基础模型是否可以改善基于深度学习的影像生物标志物的发现,特别是在有限的数据集规模情况下。
研究团队利用11,467个放射影像病变的综合数据集,通过自我监督学习训练卷积编码器,开发了一个癌症影像生物标志物发现的基础模型,并在基于癌症影像生物标志物的独特且临床相关应用中对其进行了评估。结果发现,该基础模型有助于更好、更高效地学习影像生物标志物,并产生了特定任务的模型,在下游任务上显著优于传统的监督和其他预训练模型,尤其是在训练数据集规模非常有限的情况下。此外,基础模型对输入变量更稳定,并显示出与基础生物学的强烈关联。

文章发表在Nature Machine Intelligence
首先,研究团队利用2312名患者的计算机断层扫描(CT)成像中识别的11,467个经注释的病变数据集进行了自我监督预训练(图1a),开发了一个深度学习基础模型。该模型首先通过对病变解剖部位进行分类,从而进行技术验证(用例1)。随后,该模型被应用于两个临床相关应用:开发预测肺结节恶性程度的诊断生物标志物(用例2)和非小细胞肺癌(NSCLC)肿瘤的预后生物标志物(用例3;图1b)。

图1. 研究概览。
01 预训练策略选择
研究人员将简单的自动编码器预训练和几种最先进的自监督预训练方法(即SimCLR、SwAV和NNCLR)与研究中开发的SimCLR改进版进行了比较。通过比较在从每个所选策略中提取特征上训练的线性分类器,评估了病变解剖部位分类的技术验证用例的预训练策略。结果显示,SimCLR改进版超过了所有其他预训练方法的平衡准确度(图2a)和平均精度(图2b),实现了0.779的平衡准确度,以及0.847的平均精度。
用例1:病变解剖部位分类
作为基础模型的技术验证,研究人员开发了分类模型来预测训练和调整数据集上的解剖部位,共3830个病变(用例1,图1b)。结果发现,与比较的基线方法相比,基础模型的实现显示出优势(图2c,d)。微调基础模型的平均精度为0.857,在平均精度层面显著优于所有基线方法。平衡准确度也有所改善,为0.804。
用例2:结节恶性程度预测
为了评估基础模型的普适性,研究人员选择了一个非分布任务和分类模型来预测LUNA16数据集中507个肺结节的恶性程度(图1b中的用例2),然后在170个结节的单独测试集进行了性能评估。结果显示,微调基础模型的曲线下面积(AUC)为0.944,平均精度为0.953,显著优于大多数基线实现性能(图2e,f)。对于从该基础模型中提取的特征,类似于用例1,其性能超过了基于基线特征的实现性能。
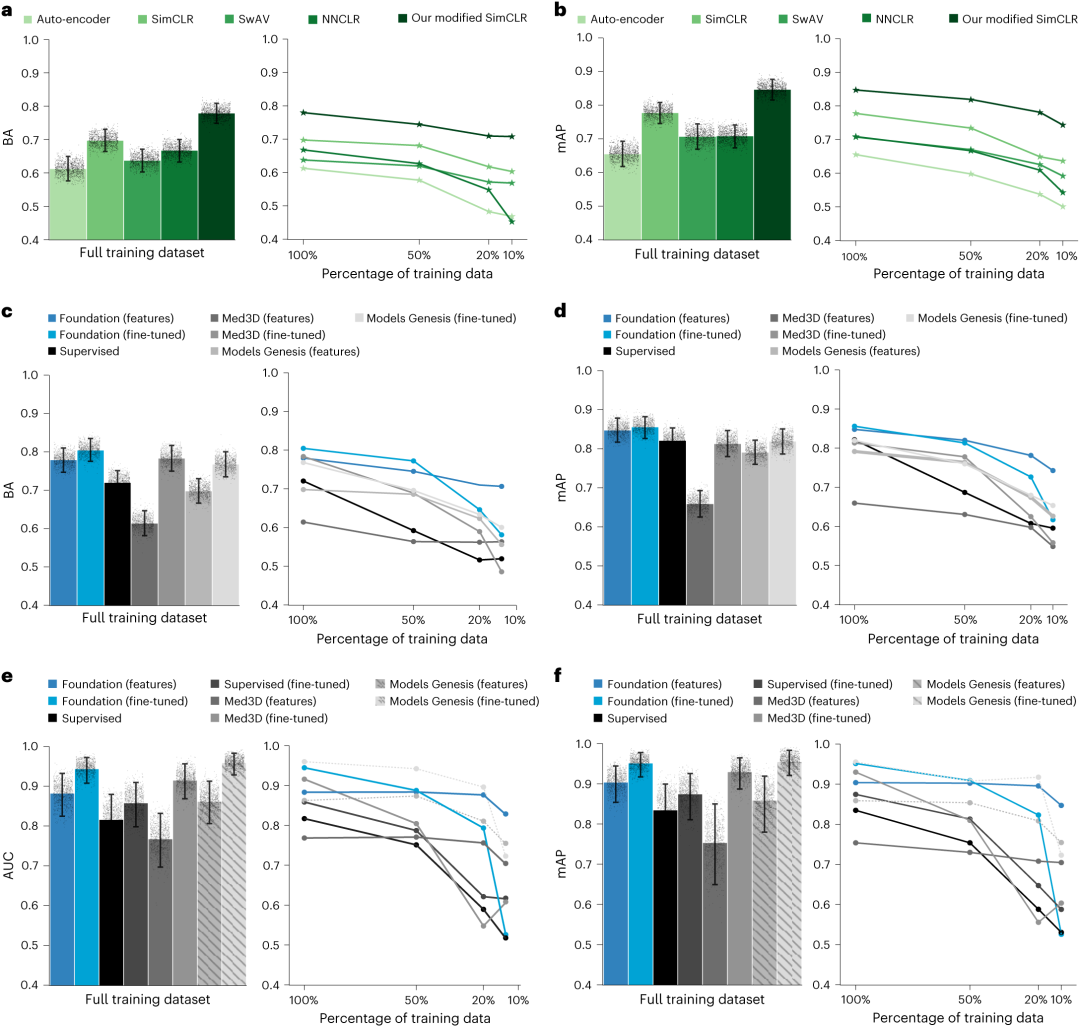
图2. 病变解剖部位(用例1)和结节恶性分类(用例2)的预训练策略和性能评估的比较。
用例3:NSCLC预后
研究团队在临床相关用例3中评估了新基础模型的有效性,以捕获NSCLC的预后放射学表型。使用来自HarvardRT队列的数据训练和调整预测模型,以预测治疗后2年的总生存期,然后比较基础模型和基线实现在两个独立测试队列中的性能,LUNG1和RADIO (图3)。
对于LUNG1队列,在基础模型中采用线性分类器提取的特征,AUC为0.638,超过了所有基线性能(图3a)。研究显示基础模型提供了最好的分层,表明其能够根据死亡率确定适当的风险组。对于RADIO队列,基础模型显示出最佳性能,AUC为0.653(图3c)。
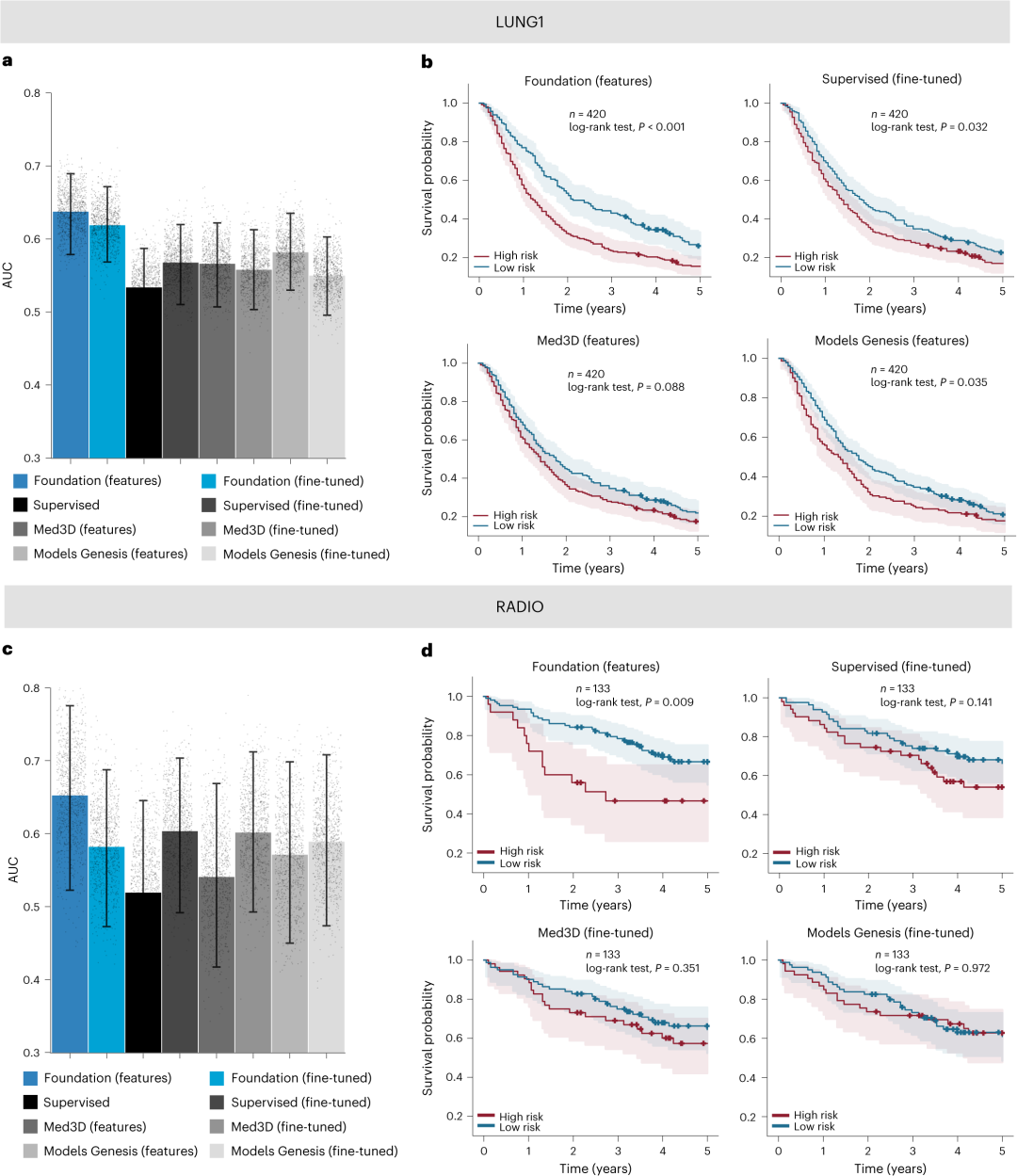
图3. NSCLC预测基础模型的性能(用例3)。
02 基础模型的稳定性
研究人员通过测试-重测试场景和阅片者间变异性分析评估了基础模型的稳定性。在LUNG1和RADIO队列中整体表现最好的模型的预测:基础模型和微调基础模型具有高稳定性,组内相关系数(ICC)值分别为0.984和0.966。此外,两个网络的测试-重测试特征具有很强的相关性(图4a,b)。此外,基础模型在对抗模拟阅片者间特征差异和预测性能变化方面具有显著更高的稳定性(P < 0.05)(图4d,e)。
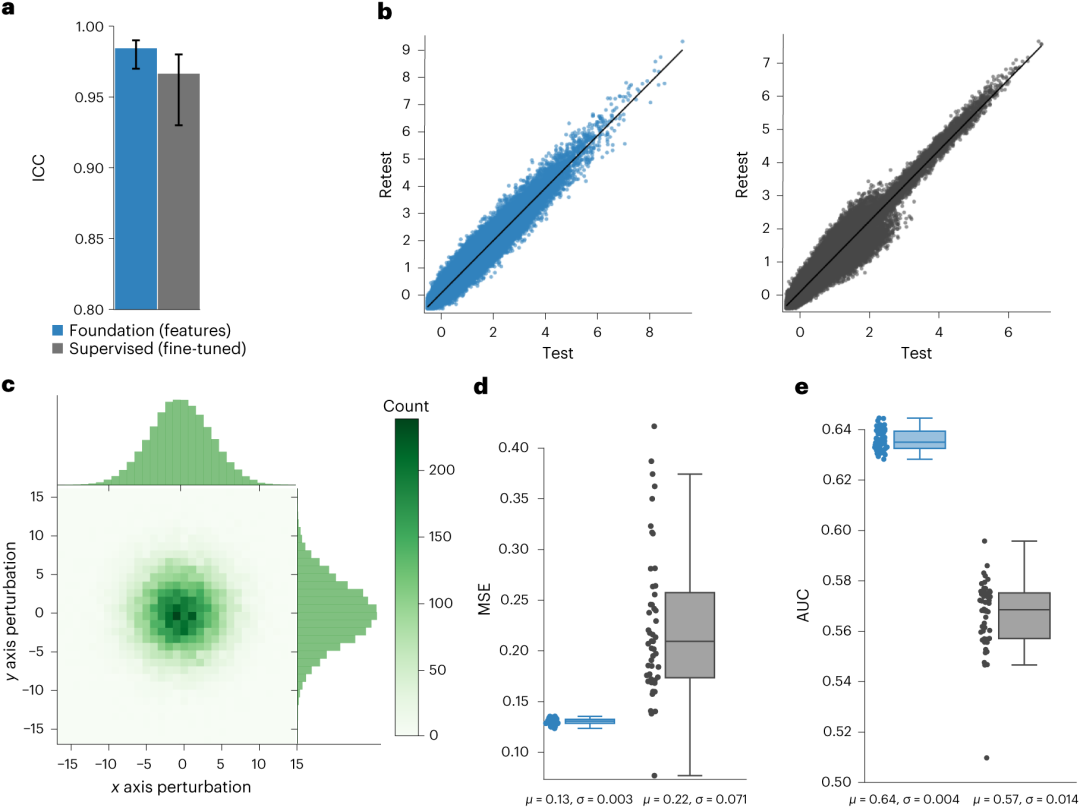
图4.输入和测试-重测试基础模型的稳定性。
03 微调基础模型的显著性
对于每个用例,重点主要围绕肿瘤内或附近的组织,这与证明肿瘤微环境对癌症发展和预后的影响的研究一致。在用例1中(图5a),重点主要集中在病变周围的区域,如肺中的实质和骨区域以及纵隔病变中的气管。对于用例2(图5b),突出显示了结节的组织而避开了高密度骨区域。用例3(图5c)主要集中于肿瘤质心周围的区域,高密度骨区域也有一定的贡献。总体而言,这些发现有助于网络预测的区域根据具体用例变化,其中肿瘤和周围组织发挥着关键作用。
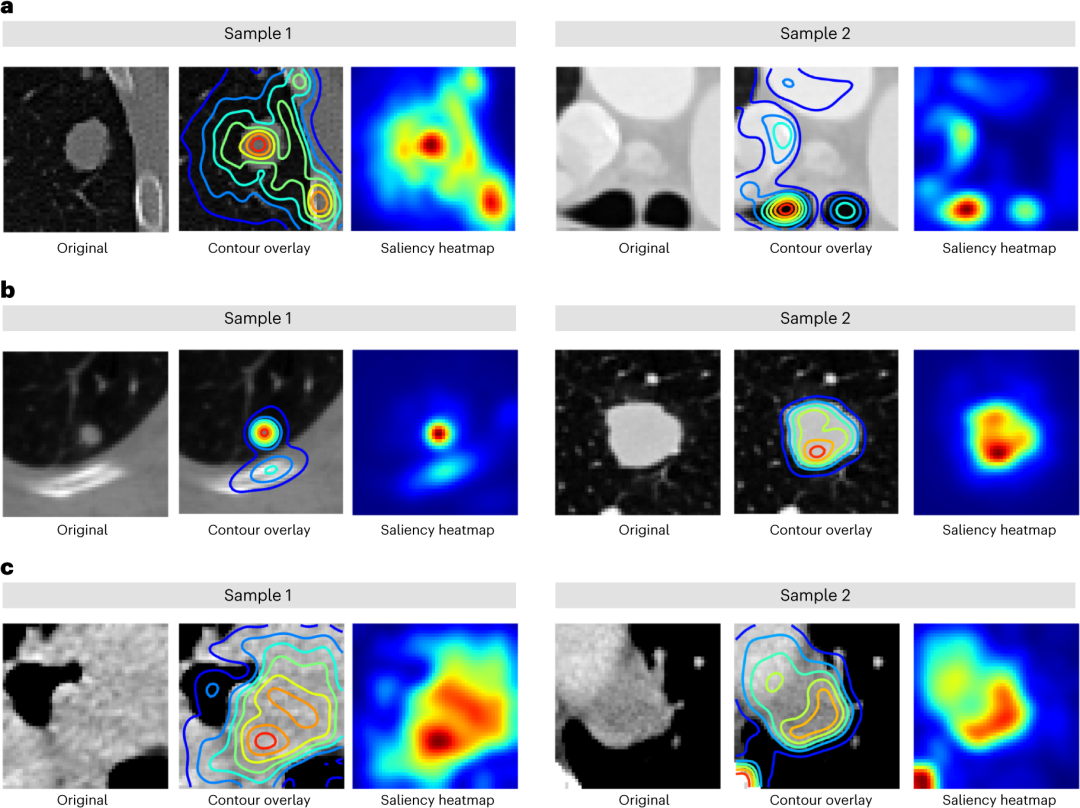
图5.微调基础模型的显著性图。
04 基础模型的基本生物学基础
通过分析RADIO数据集中130名参与者的与模型预测相关的基因表达数据,研究人员探究了基础模型的生物学基础。研究选择了前500个基因并进行了相关性分析,将基础模型和微调基础模型预测与基因表达谱进行了比较,发现基因表达谱与基础模型预测之间的绝对相关系数显著较高,表明与潜在的肿瘤生物学有更强的相关性(图6a)。此外,基因集富集分析显示,基础模型显示出免疫相关途径的富集模式,微调基础模型没有观察到可识别的模式(图6b)。
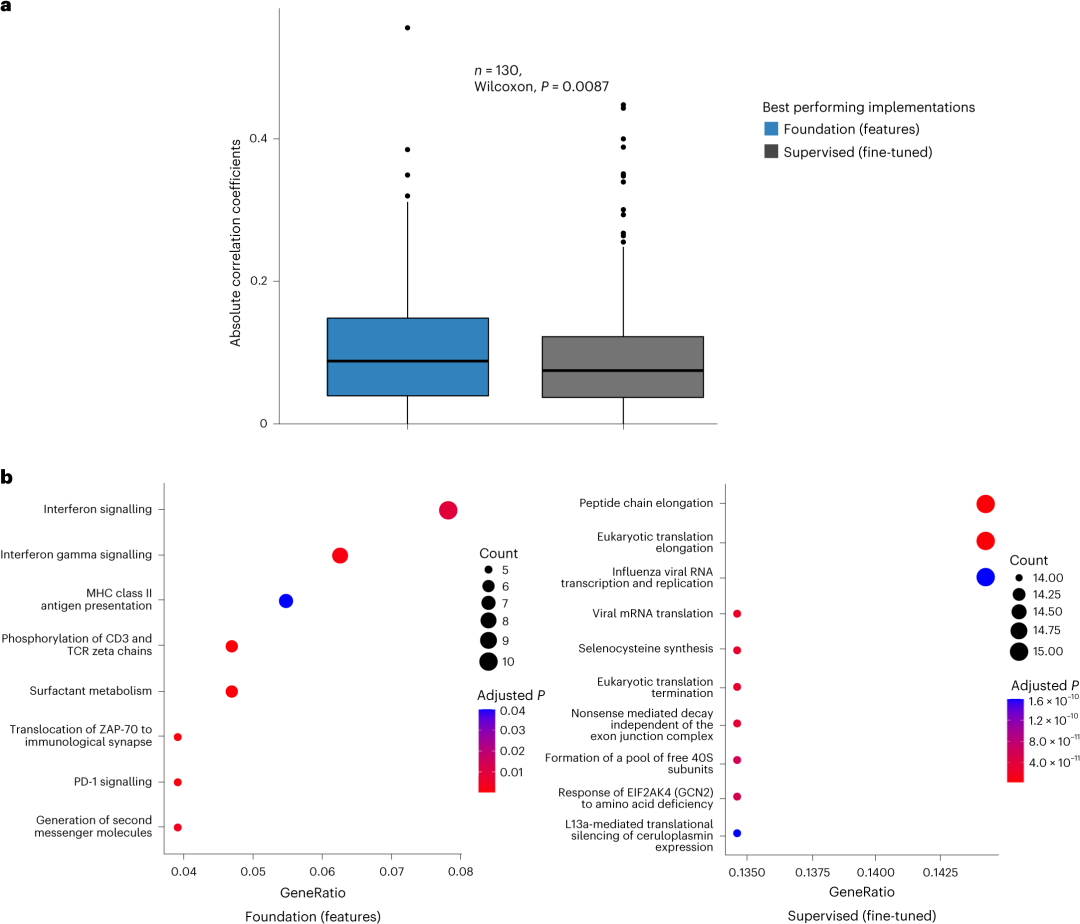
图6.基础模型的基本生物学基础。
综上所述,该研究证明了基础模型在发现新影像生物标志物方面的巨大潜力,及其在数据集有限的情况下的特殊优势。这些生物标志物可能扩展到其他临床应用场景,并可以加速影像生物标志物向临床环境更广泛的转化。该文章第一作者Suraj Pai表示:“鉴于影像生物标志物研究是为了回答越来越具体的研究问题而量身定制的,我们相信这一工作将使研究更加准确和高效。”
此前,Moffitt癌症中心的研究人员利用PET/CT图像,以非侵入性的方式检测了NSCLC患者的PD-L1生物标志物表达水平,进而预测了患者对治疗的反应。该研究确定了一种有效且稳定的深度学习评分方法来检测PD-L1表达状态,并可作为指导免疫治疗的预后生物标志物。(点击查看此前报道)
参考资料:
1.Pai, S., Bontempi, D., Hadzic, I. et al. Foundation model for cancer imaging biomarkers. Nat Mach Intell 6, 354–367 (2024). https://doi.org/10.1038/s42256-024-00807-9
2.https://medicalxpress.com/news/2024-05-foundation-cancer-imaging-biomarkers.html
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言














#癌症# #生物标志物# #基础模型#
9